1990年代の後半になって「ゲノムプロジェクト」という言葉がひんぱんに聞かれるようになった。生き物が形をつくり上げ、生きていくのに必要な遺伝情報の全てがゲノムに書かれている。ゲノムは「設計図」。生物の個体が自身を書き表す言葉の集大成だ。そのすべてを、まるごと読んでみよう、というのがゲノムプロジェクトだ。例えばヒトゲノムといってもただ一種類ではなく、私には私の、あなたにはあなたのゲノムがあって、親兄弟とも少しずつ違っている。このゲノムを解読することで、生物の形がどのようにつくられるのか、またどうして病気になったりするのか、また人の個性がどうやって生まれるのかも分かるかもしれない。
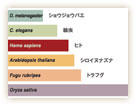
ヒトゲノムプロジェクトは2002年に完了宣言が大きく報じられた。ゲノム上のATGCの塩基配列が、紙またはコンピュータ上の文字情報として置き換えられたことになる。しかし、それはまだ無機質な文字の羅列に過ぎない。そこから意味のある情報を読み取り、情報を分類し、さらに互いの関連を明らかにしていく必要がある。ゲノムの中には数多くの遺伝子があるが、実は遺伝子でない部分も多い。その中には、遺伝子の働きを活性化したり抑えたりする重要な部分がある一方、昔の遺伝子の名残など、不要な部分も多く含まれることが分かっている。ヒトをはじめゲノムプロジェクトが終了したさまざまな生物の遺伝子数が推定されているが(図1)、ヒトの遺伝子数は2万程度で、従来予想されていた数より少なかった。また他の生物と大差はないという驚くべき結果だ。この数少ない遺伝子をどう使い回すかが、ヒトのような複雑な生物の発生を知る上では重要だが、まずは基本的な遺伝子の働きを知る必要がある。

ゲノム上にある遺伝子は、百科辞典のように項目ごとに内容が整理されて順に並べられているわけではない。一つひとつの遺伝子の機能を調べ、形をつくるのに必要な遺伝子、生きていくのに必要な遺伝子、遺伝情報を子孫に伝えるのに必要な遺伝子・・・といった項目ごとに全ての遺伝子をグループ分けしていく必要がある。遺伝子の基本的な働きは、異なる生物の間でも似通っていると考えられるので、発生に関わる遺伝子の働きを知るためには、体の構造がシンプルな生物を使って調べるのが近道だ。
発生ゲノミクス研究チームの杉本亜砂子博士はこうした試みをいち早く行なってきた。ゲノムに含まれる情報すべてをもとにして生物を理解する「ゲノム機能学」と呼ばれる新しい分野だ。ここでは形づくりの過程がよく知られた線虫が用いられている。線虫の強みはシンプルな体の構造で、全てのもとになる1個の受精卵がいつ、どのように分裂して、体をつくる959個の細胞ができてくるかが完全に調べられていることだ(図2)。
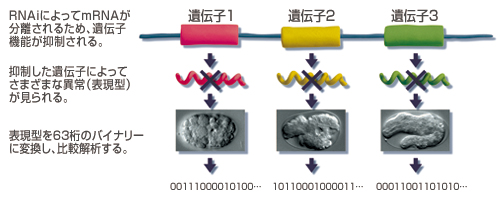
杉本研究チームはゲノム上にある全ての遺伝子を対象に、RNAi法によって機能を阻害したとき起こる変化を調べてきた。それによって何に必要な遺伝子であるかが分かるからだ。杉本博士によれば、線虫がもつ約2万の遺伝子のうち、発生や生存に必須の遺伝子は全体の約1/3にあたる6,000個程度あるという。胚の形を顕微鏡で観察し、発生の途中でどのような変化が起きたかを調べ、似たものどうしを集めてゆくと、それらを「初期の細胞分裂」、「細胞の運命決定」、「最終的な形づくりのプロセス」に働く遺伝子群として分類することが出来た(図3)。このようにして発生のステップや生命現象ごとに分類していけば、そのグループの中での遺伝子の相互関係を理解できるようになるはずだ。少なくとも一気に2万を相手にするより簡単だろう。
膨大な量の遺伝情報を分類し、理解しやすくする。大網に集めた魚を種類ごとに小さな生け簀に分けていく作業、とでも言ったらいいだろうか。現在のゲノム学は、いきなり全体を見る前に、解析しやすく情報を整理する段階にあるといえる。
ゲノム情報の公開と同時期に、RNAi法が線虫でタイミングよく発見されたことも大きいが、それでも全ての遺伝子についてノックダウン実験を行い、表現型の網羅的な解析とデータベースの作成を行うのはやはり大変な作業だったはずだ。個人的に興味のある現象に着目するだけなら、網羅的な解析を手がけることは時間的、金銭的にも不利となる。杉本博士が敢えてそれを始めたのはなぜだったのだろうか。
RNAi法に必要な試料(cDNAライブラリー)は国立遺伝学研究所の小原教授から提供された。それを受け取る際の約束が、「得られた表現型の情報を、個人的な興味のある・なしで分け隔てせず、すべてを公表すること」だった。自分にとって現在は不要でも、他の研究者にとっては宝の山となるかもしれない。それは自分を育ててくれた研究者コミュニティへの恩返しでもある、と杉本博士は語る。線虫の研究者コミュニティでは、互いに協力し合うという基本姿勢から、研究試料や情報の共有を進めてきた。そのコミュニティから大きな恩恵を受けてきたと考える杉本博士が、発生関連遺伝子を誰でも自由に調べることのできるデータベースをつくろうとしたのは、ごく自然な流れだったという。このデータベースはゲノムに書き込まれた発生プログラムを私たちが読み解くための基礎となるものだ。
ゲノム情報が整理・分類された後、それらを互いに関連付けていく仕事はどのように進められていくのか。その試みとして現在最も進んでいる分野の一つが、体内時計の研究である。システムバイオロジー研究チームの上田泰己博士は精力的かつ体系的な解析でこの分野をリードしている。
体内時計は私たちの日々の生活で実感され、生物全般にも広く見られる現象として重要だ。24時間のサイクルに沿って、さまざまな遺伝子の発現が周期的にON/OFFすることで私たちの体内時計は回っている。朝、働く遺伝子もあれば、寝ている間に働く遺伝子もあるという具合だ。上田研究チームによるマイクロアレイを用いたゲノムワイドな探索の結果、発現が1日24時間の周期で変化する遺伝子が同定されている。時計のコアがあるといわれる脳の視交叉上核でおよそ100遺伝子、その他の体内器官(たとえば肝臓など)で数百の遺伝子が周期的な発現を示した(図4)。この多数の遺伝子の周期的な発現をコントロールしているのが、時計の振動子とも言える16の「時計遺伝子」だ。現在、これらの遺伝子が複雑な転写ネットワークを形成し、約24時間の発現リズムを生み出すメカニズムが解き明かされつつある。
16の時計遺伝子は、それぞれ、朝・昼・夜などの時間に高い発現を示す。遺伝子発現のタイミングは転写調節領域とそこに結合する転写因子によって決められている。そこで彼らは、この時間特異的な発現をもたらす調節領域のDNA配列を丹念に調べ、それぞれ朝配列(E/E'box)、昼配列(D-box)、夜配列(RRE)を見つけ出した。なかでも朝配列は重要で、16遺伝子のうち9つがこの配列をもち、朝配列の制御を乱すと体内時計全体が大きく乱れた。
実は、これらの時計遺伝子は全て転写因子をコードしている。そのため、互いの調節領域に結合して発現を活性化したり、抑制したり、非常に複雑なネットワークを形成し、いわば三つ巴のような関係で結ばれていた(図5)。朝を中心とするこの三つ巴の関係が、それぞれの遺伝子発現に時間差を生じ、朝・昼・夜の周期的なリズムを生み出していたのだ。
この、朝が大事、というのは昔のことわざ「早起きは三文の得」を思い起こさせる。24時間から少しずれた体内時計を地球の自転に合わせるために、光や熱などの外界からの刺激によって体内時計をリセットする機能が朝に働くことが知られている。不眠症や時差ぼけなどの体内時計の異常にも、この「朝のリセット機能」を有効に生かす治療法(高照度光照射法)が行われている。あながち迷信というわけでもなさそうだ。
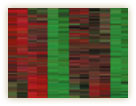
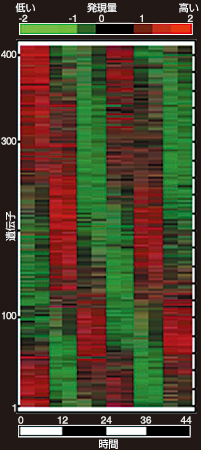
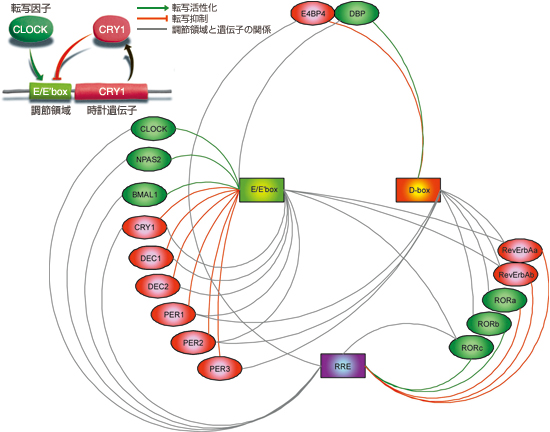
彼らが朝・昼・夜配列を見つけ、時計ネットワークの全体像をつかむには、それぞれ約1,000種類もの配列を試さなければいけなかったという。どうやって、この気の遠くなるような実験をしたのだろうか。そこには2つの技術的なブレイクスルーがあった。一つは培養細胞を用いて遺伝子の発現量を測る方法だ。調節領域と思われるDNA配列を発光タンパク遺伝子(ルシフェラーゼと呼ばれる蛍由来の遺伝子)につなぎ、培養細胞に導入して、細胞から出る光を測った(図6)。培養細胞への遺伝子導入という技術そのものは以前からあったが、従来の方法では一つの配列を解析するのに3~6ヵ月を要したのに対し、彼らが確立した方法では、それがたった1週間ほどに短縮された。
さらに効率よく多くの実験結果を得るためには、実験そのものの時間短縮に加え、同時並行で数多くの実験を行うことが必要だ。そのためには、人手を増やしたり、無理な長時間労働を強いるのではなく、機械化をめざす。彼らは、384サンプル×12プレートで合計4,608サンプルの発光を自動的に解析できるハイスループット解析システムを開発し、それを数台並べて1万個以上のサンプルを同時に解析することを可能にしている(図6)。
これらの画期的な方法により、遺伝子発現量の時間的な変化をまさにリアルタイムで捉えられるようになり、時計遺伝子群が織りなす転写ネットワークの解明へとつながったのだ。
ゲノムを相手にする限り、常に膨大な量の情報や研究試料との戦いとなる。それらを楽々と扱うための技術革新が今後の課題だ。それには、ナノテクノロジーを応用してコンパクトな実験系をつくり出すことも含まれる。細胞1個からでも必要な情報が取れるようになれば、サンプル調製のコストも、研究室のスペースも、情報を取るための時間も削減できる・・・といってもそれは簡単なことではない。意外なことに、技術革新のためのツボは人的な交流なのだと上田博士は言う。ナノテクをはじめとした先端技術は、日本が世界に誇る分野だ。しかし実際には、どこの誰が優れた技術を持っているかが分からない。インターネットが発達して、ちょっとした疑問は検索サイトで調べれば答えが出る、そんな時代でも、肝心の情報は足で探し、人づてで得るしかないという。研究分野の枠を越え、ニーズとシーズを引き合わせる。研究の進展の鍵を握っているのは、やはりひらめきを実現しようとする研究者の情熱だ。
時計遺伝子のネットワーク解明は、時差ボケや不眠症といった病気の原因解明と治療にも役立つ可能性をもっている。しかし、発生生物学とは一見縁がなさそうに見える。なぜ、体内時計なのか。
発生という現象には空間(3次元)的な変化と時間(1次元)的な変化が含まれている。それを合わせると4次元的変化となる。ゲノム上の数万の遺伝子を対象に、4次元的変化を全て捉え、さらに遺伝子の間の相互関係を解き明かすことは複雑すぎる。そこで空間的な変化をもたず時間的な変化だけをもつ体内時計に着目した。体内時計をモデルケースに、ゲノム上の大量の情報と物質を一気に扱うための研究体制を整えれば、そのあとにはさまざまな問題が解決しやすくなっているはずだ。そこで改めて代謝や発生という生物学上の難しい問題にアプローチしていくという戦略だ。
ゲノムプロジェクト以前の1990年代は、分子生物学がそれまでの生物の研究スタイルを大きく変えた時代だった。それまで生物学は、個々の生物がどんな生活をしているかを調べる学問だった。DNAが生物の遺伝情報を担う共通の分子だと分かってから、生命現象は分子のことばで語られるようになった。研究者はそれぞれが自分の研究に関わる遺伝子の配列を読み、配列から予想されるタンパクの機能を検証し、遺伝子が生体内でもつ機能を突然変異体を用いて一つひとつ調べてきた。
現在、ゲノムプロジェクトを経て、生物がもっている遺伝子セットのリストアップが進んでいる。完全な遺伝子のリストができ上がれば、その中から候補となるものを選び出していくのは有限の作業だ。生命現象を分子のことばで書き記そうとする分子生物学を越えて、ゲノムに含まれる情報を理解しやすいように分類するゲノム機能学や、物質のうつりかわりと網の目のような因果関係の全体を捉えようとするシステム生物学が生まれた。分解から再び全体へ。生き物のもつ複雑さが、まるごと、ありのままに理解されようとしている。その理解の先には、私たちが自分自身のことをもっとよく知りたい、という欲求を満たすだけでなく、生きていることの不思議さ、生命の尊さを強く感じ、ヒトを含めた地球上の様々な生き物で構成される生命のネットワークに対しても愛おしさを感じられるような未来が待っているかもしれない。

